行为识别模型¶
C2D¶
Abstract¶
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time. In this paper, we present non-local operations as a generic family of building blocks for capturing long-range dependencies. Inspired by the classical non-local means method in computer vision, our non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures. On the task of video classification, even without any bells and whistles, our non-local models can compete or outperform current competition winners on both Kinetics and Charades datasets. In static image recognition, our non-local models improve object detection/segmentation and pose estimation on the COCO suite of tasks.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x8x1 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
73.44 |
91.00 |
67.2 |
87.8 |
10 clips x 3 crop |
33G |
24.3M |
|||
8x8x1 |
MultiStep |
224x224 |
8 |
ResNet101 |
ImageNet |
74.97 |
91.77 |
x |
x |
10 clips x 3 crop |
63G |
43.3M |
|||
8x8x1 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
73.89 |
91.21 |
71.9 |
90.0 |
10 clips x 3 crop |
19G |
24.3M |
|||
16x4x1 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
74.97 |
91.91 |
x |
x |
10 clips x 3 crop |
39G |
24.3M |
The values in columns named after “reference” are the results reported in the original repo, using the same model settings.
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train C2D model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/c2d/c2d_r50-in1k-pre_8xb32-8x8x1-100e_kinetics400-rgb.py \
--seed 0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test C2D model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/c2d/c2d_r50-in1k-pre_8xb32-8x8x1-100e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@article{XiaolongWang2017NonlocalNN,
title={Non-local Neural Networks},
author={Xiaolong Wang and Ross Girshick and Abhinav Gupta and Kaiming He},
journal={arXiv: Computer Vision and Pattern Recognition},
year={2017}
}
C3D¶
Learning Spatiotemporal Features with 3D Convolutional Networks
Abstract¶
We propose a simple, yet effective approach for spatiotemporal feature learning using deep 3-dimensional convolutional networks (3D ConvNets) trained on a large scale supervised video dataset. Our findings are three-fold: 1) 3D ConvNets are more suitable for spatiotemporal feature learning compared to 2D ConvNets; 2) A homogeneous architecture with small 3x3x3 convolution kernels in all layers is among the best performing architectures for 3D ConvNets; and 3) Our learned features, namely C3D (Convolutional 3D), with a simple linear classifier outperform state-of-the-art methods on 4 different benchmarks and are comparable with current best methods on the other 2 benchmarks. In addition, the features are compact: achieving 52.8% accuracy on UCF101 dataset with only 10 dimensions and also very efficient to compute due to the fast inference of ConvNets. Finally, they are conceptually very simple and easy to train and use.

Results and Models¶
UCF-101¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
16x1x1 |
112x112 |
8 |
c3d |
sports1m |
83.08 |
95.93 |
10 clips x 1 crop |
38.5G |
78.4M |
The author of C3D normalized UCF-101 with volume mean and used SVM to classify videos, while we normalized the dataset with RGB mean value and used a linear classifier.
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.
For more details on data preparation, you can refer to UCF101.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train C3D model on UCF-101 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/c3d/c3d_sports1m-pretrained_8xb30-16x1x1-45e_ucf101-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test C3D model on UCF-101 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/c3d_sports1m-pretrained_8xb30-16x1x1-45e_ucf101-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@ARTICLE{2014arXiv1412.0767T,
author = {Tran, Du and Bourdev, Lubomir and Fergus, Rob and Torresani, Lorenzo and Paluri, Manohar},
title = {Learning Spatiotemporal Features with 3D Convolutional Networks},
keywords = {Computer Science - Computer Vision and Pattern Recognition},
year = 2014,
month = dec,
eid = {arXiv:1412.0767}
}
CSN¶
Video Classification With Channel-Separated Convolutional Networks
Abstract¶
Group convolution has been shown to offer great computational savings in various 2D convolutional architectures for image classification. It is natural to ask: 1) if group convolution can help to alleviate the high computational cost of video classification networks; 2) what factors matter the most in 3D group convolutional networks; and 3) what are good computation/accuracy trade-offs with 3D group convolutional networks. This paper studies the effects of different design choices in 3D group convolutional networks for video classification. We empirically demonstrate that the amount of channel interactions plays an important role in the accuracy of 3D group convolutional networks. Our experiments suggest two main findings. First, it is a good practice to factorize 3D convolutions by separating channel interactions and spatiotemporal interactions as this leads to improved accuracy and lower computational cost. Second, 3D channel-separated convolutions provide a form of regularization, yielding lower training accuracy but higher test accuracy compared to 3D convolutions. These two empirical findings lead us to design an architecture – Channel-Separated Convolutional Network (CSN) – which is simple, efficient, yet accurate. On Sports1M, Kinetics, and Something-Something, our CSNs are comparable with or better than the state-of-the-art while being 2-3 times more efficient.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
32x2x1 |
224x224 |
8 |
ResNet152 (IR) |
IG65M |
82.87 |
95.90 |
10 clips x 3 crop |
97.63G |
29.70M |
|||
32x2x1 |
224x224 |
8 |
ResNet152 (IR+BNFrozen) |
IG65M |
82.84 |
95.92 |
10 clips x 3 crop |
97.63G |
29.70M |
|||
32x2x1 |
224x224 |
8 |
ResNet50 (IR+BNFrozen) |
IG65M |
79.44 |
94.26 |
10 clips x 3 crop |
55.90G |
13.13M |
|||
32x2x1 |
224x224 |
x |
ResNet152 (IP) |
None |
77.80 |
93.10 |
10 clips x 3 crop |
109.9G |
33.02M |
x |
||
32x2x1 |
224x224 |
x |
ResNet152 (IR) |
None |
76.53 |
92.28 |
10 clips x 3 crop |
97.6G |
29.70M |
x |
||
32x2x1 |
224x224 |
x |
ResNet152 (IP+BNFrozen) |
IG65M |
82.68 |
95.69 |
10 clips x 3 crop |
109.9G |
33.02M |
x |
||
32x2x1 |
224x224 |
x |
ResNet152 (IP+BNFrozen) |
Sports1M |
79.07 |
93.82 |
10 clips x 3 crop |
109.9G |
33.02M |
x |
||
32x2x1 |
224x224 |
x |
ResNet152 (IR+BNFrozen) |
Sports1M |
78.57 |
93.44 |
10 clips x 3 crop |
109.9G |
33.02M |
x |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
The infer_ckpt means those checkpoints are ported from VMZ.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train CSN model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/csn/ircsn_ig65m-pretrained-r152_8xb12-32x2x1-58e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test CSN model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/csn/ircsn_ig65m-pretrained-r152_8xb12-32x2x1-58e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{inproceedings,
author = {Wang, Heng and Feiszli, Matt and Torresani, Lorenzo},
year = {2019},
month = {10},
pages = {5551-5560},
title = {Video Classification With Channel-Separated Convolutional Networks},
doi = {10.1109/ICCV.2019.00565}
}
@inproceedings{ghadiyaram2019large,
title={Large-scale weakly-supervised pre-training for video action recognition},
author={Ghadiyaram, Deepti and Tran, Du and Mahajan, Dhruv},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={12046--12055},
year={2019}
}
I3D¶
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Abstract¶
The paucity of videos in current action classification datasets (UCF-101 and HMDB-51) has made it difficult to identify good video architectures, as most methods obtain similar performance on existing small-scale benchmarks. This paper re-evaluates state-of-the-art architectures in light of the new Kinetics Human Action Video dataset. Kinetics has two orders of magnitude more data, with 400 human action classes and over 400 clips per class, and is collected from realistic, challenging YouTube videos. We provide an analysis on how current architectures fare on the task of action classification on this dataset and how much performance improves on the smaller benchmark datasets after pre-training on Kinetics. We also introduce a new Two-Stream Inflated 3D ConvNet (I3D) that is based on 2D ConvNet inflation: filters and pooling kernels of very deep image classification ConvNets are expanded into 3D, making it possible to learn seamless spatio-temporal feature extractors from video while leveraging successful ImageNet architecture designs and even their parameters. We show that, after pre-training on Kinetics, I3D models considerably improve upon the state-of-the-art in action classification, reaching 80.9% on HMDB-51 and 98.0% on UCF-101.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
32x2x1 |
224x224 |
8 |
ResNet50 (NonLocalDotProduct) |
ImageNet |
74.80 |
92.07 |
10 clips x 3 crop |
59.3G |
35.4M |
|||
32x2x1 |
224x224 |
8 |
ResNet50 (NonLocalEmbedGauss) |
ImageNet |
74.73 |
91.80 |
10 clips x 3 crop |
59.3G |
35.4M |
|||
32x2x1 |
224x224 |
8 |
ResNet50 (NonLocalGauss) |
ImageNet |
73.97 |
91.33 |
10 clips x 3 crop |
56.5 |
31.7M |
|||
32x2x1 |
224x224 |
8 |
ResNet50 |
ImageNet |
73.47 |
91.27 |
10 clips x 3 crop |
43.5G |
28.0M |
|||
dense-32x2x1 |
224x224 |
8 |
ResNet50 |
ImageNet |
73.77 |
91.35 |
10 clips x 3 crop |
43.5G |
28.0M |
|||
32x2x1 |
224x224 |
8 |
ResNet50 (Heavy) |
ImageNet |
76.21 |
92.48 |
10 clips x 3 crop |
166.3G |
33.0M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train I3D model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/i3d/i3d_imagenet-pretrained-r50_8xb8-32x2x1-100e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test I3D model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/i3d/i3d_imagenet-pretrained-r50_8xb8-32x2x1-100e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{inproceedings,
author = {Carreira, J. and Zisserman, Andrew},
year = {2017},
month = {07},
pages = {4724-4733},
title = {Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset},
doi = {10.1109/CVPR.2017.502}
}
@article{NonLocal2018,
author = {Xiaolong Wang and Ross Girshick and Abhinav Gupta and Kaiming He},
title = {Non-local Neural Networks},
journal = {CVPR},
year = {2018}
}
MViT V2¶
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
Abstract¶
In this paper, we study Multiscale Vision Transformers (MViTv2) as a unified architecture for image and video classification, as well as object detection. We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections. We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work. We further compare MViTv2s’ pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute. Without bells-and-whistles, MViTv2 has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 58.7 boxAP on COCO object detection as well as 86.1% on Kinetics-400 video classification.

Results and Models¶
Models with * in
Inference resultsare ported from the repo SlowFast and tested on our data, and models inTraining resultsare trained in MMAction2 on our data.The values in columns named after
referenceare copied from paper, andreference*are results using SlowFast repo and trained on our data.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
MaskFeat fine-tuning experiment is based on pretrain model from MMSelfSup, and the corresponding reference result is based on pretrain model from SlowFast.
Due to the different versions of Kinetics-400, our training results are different from paper.
Due to the training efficiency, we currently only provide MViT-small training results, we don’t ensure other config files’ training accuracy and welcome you to contribute your reproduction results.
We use
repeat augmentin MViT training configs following SlowFast. Repeat augment takes multiple times of data augment for one video, this way can improve the generalization of the model and relieve the IO stress of loading videos. And please note that the actual batch size isnum_repeatstimes ofbatch_sizeintrain_dataloader.
Inference results¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
224x224 |
MViTv2-S* |
From scratch |
81.1 |
94.7 |
5 clips x 1 crop |
64G |
34.5M |
||||
32x3x1 |
224x224 |
MViTv2-B* |
From scratch |
82.6 |
95.8 |
5 clips x 1 crop |
225G |
51.2M |
||||
40x3x1 |
312x312 |
MViTv2-L* |
From scratch |
85.4 |
96.2 |
5 clips x 3 crop |
2828G |
213M |
Something-Something V2¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
uniform 16 |
224x224 |
MViTv2-S* |
K400 |
68.1 |
91.0 |
1 clips x 3 crop |
64G |
34.4M |
||||
uniform 32 |
224x224 |
MViTv2-B* |
K400 |
70.8 |
92.7 |
1 clips x 3 crop |
225G |
51.1M |
||||
uniform 40 |
312x312 |
MViTv2-L* |
IN21K + K400 |
73.2 |
94.0 |
1 clips x 3 crop |
2828G |
213M |
Training results¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference* top1 acc |
reference* top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
224x224 |
MViTv2-S |
From scratch |
80.6 |
94.7 |
5 clips x 1 crop |
64G |
34.5M |
|||||
16x4x1 |
224x224 |
MViTv2-S |
K400 MaskFeat |
81.8 |
95.2 |
10 clips x 1 crop |
71G |
36.4M |
the corresponding result without repeat augment is as follows:
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference* top1 acc |
reference* top5 acc |
testing protocol |
FLOPs |
params |
|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
224x224 |
MViTv2-S |
From scratch |
79.4 |
93.9 |
5 clips x 1 crop |
64G |
34.5M |
Something-Something V2¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
uniform 16 |
224x224 |
MViTv2-S |
K400 |
68.2 |
91.3 |
1 clips x 3 crop |
64G |
34.4M |
For more details on data preparation, you can refer to
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test MViT model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/mvit/mvit-small-p244_16x4x1_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{li2021improved,
title={MViTv2: Improved multiscale vision transformers for classification and detection},
author={Li, Yanghao and Wu, Chao-Yuan and Fan, Haoqi and Mangalam, Karttikeya and Xiong, Bo and Malik, Jitendra and Feichtenhofer, Christoph},
booktitle={CVPR},
year={2022}
}
Omnisource¶
Abstract¶
We propose to train a recognizer that can classify images and videos. The recognizer is jointly trained on image and video datasets. Compared with pre-training on the same image dataset, this method can significantly improve the video recognition performance.
Results and Models¶
Kinetics-400¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
joint-training |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x8x1 |
Linear+Cosine |
224x224 |
8 |
ResNet50 |
ImageNet |
77.30 |
93.23 |
10 clips x 3 crop |
54.75G |
32.45M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train SlowOnly model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/omnisource/slowonly_r50_8xb16-8x8x1-256e_imagenet-kinetics400-rgb.py \
--seed=0 --deterministic
We found that the training of this Omnisource model could crash for unknown reasons. If this happens, you can resume training by adding the --cfg-options resume=True to the training script.
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test SlowOnly model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/omnisource/slowonly_r50_8xb16-8x8x1-256e_imagenet-kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{feichtenhofer2019slowfast,
title={Slowfast networks for video recognition},
author={Feichtenhofer, Christoph and Fan, Haoqi and Malik, Jitendra and He, Kaiming},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={6202--6211},
year={2019}
}
@article{duan2020omni,
title={Omni-sourced Webly-supervised Learning for Video Recognition},
author={Duan, Haodong and Zhao, Yue and Xiong, Yuanjun and Liu, Wentao and Lin, Dahua},
journal={arXiv preprint arXiv:2003.13042},
year={2020}
}
R2plus1D¶
A closer look at spatiotemporal convolutions for action recognition
Abstract¶
In this paper we discuss several forms of spatiotemporal convolutions for video analysis and study their effects on action recognition. Our motivation stems from the observation that 2D CNNs applied to individual frames of the video have remained solid performers in action recognition. In this work we empirically demonstrate the accuracy advantages of 3D CNNs over 2D CNNs within the framework of residual learning. Furthermore, we show that factorizing the 3D convolutional filters into separate spatial and temporal components yields significantly advantages in accuracy. Our empirical study leads to the design of a new spatiotemporal convolutional block “R(2+1)D” which gives rise to CNNs that achieve results comparable or superior to the state-of-the-art on Sports-1M, Kinetics, UCF101 and HMDB51.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x8x1 |
224x224 |
8 |
ResNet34 |
None |
69.76 |
88.41 |
10 clips x 3 crop |
53.1G |
63.8M |
|||
32x2x1 |
224x224 |
8 |
ResNet34 |
None |
75.46 |
92.28 |
10 clips x 3 crop |
213G |
63.8M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train R(2+1)D model on Kinetics-400 dataset in a deterministic option.
python tools/train.py configs/recognition/r2plus1d/r2plus1d_r34_8xb8-8x8x1-180e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test R(2+1)D model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/r2plus1d/r2plus1d_r34_8xb8-8x8x1-180e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{tran2018closer,
title={A closer look at spatiotemporal convolutions for action recognition},
author={Tran, Du and Wang, Heng and Torresani, Lorenzo and Ray, Jamie and LeCun, Yann and Paluri, Manohar},
booktitle={Proceedings of the IEEE conference on Computer Vision and Pattern Recognition},
pages={6450--6459},
year={2018}
}
SlowFast¶
SlowFast Networks for Video Recognition
Abstract¶
We present SlowFast networks for video recognition. Our model involves (i) a Slow pathway, operating at low frame rate, to capture spatial semantics, and (ii) a Fast pathway, operating at high frame rate, to capture motion at fine temporal resolution. The Fast pathway can be made very lightweight by reducing its channel capacity, yet can learn useful temporal information for video recognition. Our models achieve strong performance for both action classification and detection in video, and large improvements are pin-pointed as contributions by our SlowFast concept. We report state-of-the-art accuracy on major video recognition benchmarks, Kinetics, Charades and AVA.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4x16x1 |
Linear+Cosine |
224x224 |
8 |
ResNet50 |
None |
75.55 |
92.35 |
10 clips x 3 crop |
36.3G |
34.5M |
|||
8x8x1 |
Linear+Cosine |
224x224 |
8 |
ResNet50 |
None |
76.80 |
92.99 |
10 clips x 3 crop |
66.1G |
34.6M |
|||
8x8x1 |
Linear+MultiStep |
224x224 |
8 |
ResNet50 |
None |
76.65 |
92.86 |
10 clips x 3 crop |
66.1G |
34.6M |
|||
8x8x1 |
Linear+Cosine |
224x224 |
8 |
ResNet101 |
None |
78.65 |
93.88 |
10 clips x 3 crop |
126G |
62.9M |
|||
4x16x1 |
Linear+Cosine |
224x224 |
32 |
ResNet101 + ResNet50 |
None |
77.03 |
92.99 |
10 clips x 3 crop |
64.9G |
62.4M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train SlowFast model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/slowfast/slowfast_r50_8xb8-4x16x1-256e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test SlowFast model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/slowfast/slowfast_r50_8xb8-4x16x1-256e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{feichtenhofer2019slowfast,
title={Slowfast networks for video recognition},
author={Feichtenhofer, Christoph and Fan, Haoqi and Malik, Jitendra and He, Kaiming},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={6202--6211},
year={2019}
}
SlowOnly¶
Slowfast networks for video recognition
Abstract¶
We present SlowFast networks for video recognition. Our model involves (i) a Slow pathway, operating at low frame rate, to capture spatial semantics, and (ii) a Fast pathway, operating at high frame rate, to capture motion at fine temporal resolution. The Fast pathway can be made very lightweight by reducing its channel capacity, yet can learn useful temporal information for video recognition. Our models achieve strong performance for both action classification and detection in video, and large improvements are pin-pointed as contributions by our SlowFast concept. We report state-of-the-art accuracy on major video recognition benchmarks, Kinetics, Charades and AVA.
Results and Models¶
Kinetics-400¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4x16x1 |
Linear+Cosine |
224x224 |
8 |
ResNet50 |
None |
72.97 |
90.88 |
10 clips x 3 crop |
27.38G |
32.45M |
|||
8x8x1 |
Linear+Cosine |
224x224 |
8 |
ResNet50 |
None |
75.15 |
92.11 |
10 clips x 3 crop |
54.75G |
32.45M |
|||
8x8x1 |
Linear+Cosine |
224x224 |
8 |
ResNet101 |
None |
76.59 |
92.80 |
10 clips x 3 crop |
112G |
60.36M |
|||
4x16x1 |
Linear+MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
75.12 |
91.72 |
10 clips x 3 crop |
27.38G |
32.45M |
|||
8x8x1 |
Linear+MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
76.45 |
92.55 |
10 clips x 3 crop |
54.75G |
32.45M |
|||
4x16x1 |
Linear+MultiStep |
224x224 |
8 |
ResNet50 (NonLocalEmbedGauss) |
ImageNet |
75.07 |
91.69 |
10 clips x 3 crop |
43.23G |
39.81M |
|||
8x8x1 |
Linear+MultiStep |
224x224 |
8 |
ResNet50 (NonLocalEmbedGauss) |
ImageNet |
76.65 |
92.47 |
10 clips x 3 crop |
96.66G |
39.81M |
Kinetics-700¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4x16x1 |
Linear+MultiStep |
224x224 |
8x2 |
ResNet50 |
ImageNet |
65.52 |
86.39 |
10 clips x 3 crop |
27.38G |
32.45M |
|||
8x8x1 |
Linear+MultiStep |
224x224 |
8x2 |
ResNet50 |
ImageNet |
67.67 |
87.80 |
10 clips x 3 crop |
54.75G |
32.45M |
Kinetics-710¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x8x1 |
Linear+MultiStep |
224x224 |
8x4 |
ResNet50 |
ImageNet |
72.39 |
90.60 |
10 clips x 3 crop |
54.75G |
32.45M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train SlowOnly model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/slowonly/slowonly_r50_8xb16-4x16x1-256e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test SlowOnly model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/slowonly/slowonly_r50_8xb16-4x16x1-256e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{feichtenhofer2019slowfast,
title={Slowfast networks for video recognition},
author={Feichtenhofer, Christoph and Fan, Haoqi and Malik, Jitendra and He, Kaiming},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={6202--6211},
year={2019}
}
VideoSwin¶
Abstract¶
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally connect patches across the spatial and temporal dimensions. In this paper, we instead advocate an inductive bias of locality in video Transformers, which leads to a better speed-accuracy trade-off compared to previous approaches which compute self-attention globally even with spatial-temporal factorization. The locality of the proposed video architecture is realized by adapting the Swin Transformer designed for the image domain, while continuing to leverage the power of pre-trained image models. Our approach achieves state-of-the-art accuracy on a broad range of video recognition benchmarks, including on action recognition (84.9 top-1 accuracy on Kinetics-400 and 85.9 top-1 accuracy on Kinetics-600 with ~20xless pre-training data and ~3xsmaller model size) and temporal modeling (69.6 top-1 accuracy on Something-Something v2).

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top1 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
32x2x1 |
224x224 |
8 |
Swin-T |
ImageNet-1k |
78.90 |
93.77 |
78.84 [VideoSwin] |
93.76 [VideoSwin] |
4 clips x 3 crop |
88G |
28.2M |
|||
32x2x1 |
224x224 |
8 |
Swin-S |
ImageNet-1k |
80.54 |
94.46 |
80.58 [VideoSwin] |
94.45 [VideoSwin] |
4 clips x 3 crop |
166G |
49.8M |
|||
32x2x1 |
224x224 |
8 |
Swin-B |
ImageNet-1k |
80.57 |
94.49 |
80.55 [VideoSwin] |
94.66 [VideoSwin] |
4 clips x 3 crop |
282G |
88.0M |
|||
32x2x1 |
224x224 |
8 |
Swin-L |
ImageNet-22k |
83.46 |
95.91 |
83.1* |
95.9* |
4 clips x 3 crop |
604G |
197M |
Kinetics-700¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
32x2x1 |
224x224 |
16 |
Swin-L |
ImageNet-22k |
75.92 |
92.72 |
4 clips x 3 crop |
604G |
197M |
Kinetics-710¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
32x2x1 |
224x224 |
32 |
Swin-S |
ImageNet-1k |
76.90 |
92.96 |
4 clips x 3 crop |
604G |
197M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The values in columns named after “reference” are the results got by testing on our dataset, using the checkpoints provided by the author with same model settings.
*means that the numbers are copied from the paper.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
Pre-trained image models can be downloaded from Swin Transformer for ImageNet Classification.
For more details on data preparation, you can refer to Kinetics.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train VideoSwin model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/swin/swin-tiny-p244-w877_in1k-pre_8xb8-amp-32x2x1-30e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test VideoSwin model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/swin/swin-tiny-p244-w877_in1k-pre_8xb8-amp-32x2x1-30e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{liu2022video,
title={Video swin transformer},
author={Liu, Ze and Ning, Jia and Cao, Yue and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Hu, Han},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={3202--3211},
year={2022}
}
TANet¶
TAM: Temporal Adaptive Module for Video Recognition
Abstract¶
Video data is with complex temporal dynamics due to various factors such as camera motion, speed variation, and different activities. To effectively capture this diverse motion pattern, this paper presents a new temporal adaptive module ({\bf TAM}) to generate video-specific temporal kernels based on its own feature map. TAM proposes a unique two-level adaptive modeling scheme by decoupling the dynamic kernel into a location sensitive importance map and a location invariant aggregation weight. The importance map is learned in a local temporal window to capture short-term information, while the aggregation weight is generated from a global view with a focus on long-term structure. TAM is a modular block and could be integrated into 2D CNNs to yield a powerful video architecture (TANet) with a very small extra computational cost. The extensive experiments on Kinetics-400 and Something-Something datasets demonstrate that our TAM outperforms other temporal modeling methods consistently, and achieves the state-of-the-art performance under the similar complexity.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
dense-1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
76.25 |
92.41 |
8 clips x 3 crop |
43.0G |
25.6M |
Something-Something V1¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
46.98/49.71 |
75.75/77.43 |
16 clips x 3 crop |
43.1G |
25.1M |
|||
1x1x16 |
224x224 |
8 |
ResNet50 |
ImageNet |
48.24/50.95 |
78.16/79.28 |
16 clips x 3 crop |
86.1G |
25.1M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The values in columns named after “reference” are the results got by testing on our dataset, using the checkpoints provided by the author with same model settings. The checkpoints for reference repo can be downloaded here.
The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TANet model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/tanet/tanet_imagenet-pretrained-r50_8xb8-dense-1x1x8-100e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TANet model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/tanet/tanet_imagenet-pretrained-r50_8xb8-dense-1x1x8-100e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@article{liu2020tam,
title={TAM: Temporal Adaptive Module for Video Recognition},
author={Liu, Zhaoyang and Wang, Limin and Wu, Wayne and Qian, Chen and Lu, Tong},
journal={arXiv preprint arXiv:2005.06803},
year={2020}
}
TimeSformer¶
Is Space-Time Attention All You Need for Video Understanding?
Abstract¶
We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named “TimeSformer,” adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that “divided attention,” where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long).

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x32x1 |
224x224 |
8 |
TimeSformer (divST) |
ImageNet-21K |
77.69 |
93.45 |
1 clip x 3 crop |
196G |
122M |
|||
8x32x1 |
224x224 |
8 |
TimeSformer (jointST) |
ImageNet-21K |
76.95 |
93.28 |
1 clip x 3 crop |
180G |
86.11M |
|||
8x32x1 |
224x224 |
8 |
TimeSformer (spaceOnly) |
ImageNet-21K |
76.93 |
92.88 |
1 clip x 3 crop |
141G |
86.11M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.We keep the test setting with the original repo (three crop x 1 clip).
The pretrained model
vit_base_patch16_224.pthused by TimeSformer was converted from vision_transformer.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TimeSformer model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/timesformer/timesformer_divST_8xb8-8x32x1-15e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TimeSformer model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/timesformer/timesformer_divST_8xb8-8x32x1-15e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@misc{bertasius2021spacetime,
title = {Is Space-Time Attention All You Need for Video Understanding?},
author = {Gedas Bertasius and Heng Wang and Lorenzo Torresani},
year = {2021},
eprint = {2102.05095},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
TIN¶
Abstract¶
For a long time, the vision community tries to learn the spatio-temporal representation by combining convolutional neural network together with various temporal models, such as the families of Markov chain, optical flow, RNN and temporal convolution. However, these pipelines consume enormous computing resources due to the alternately learning process for spatial and temporal information. One natural question is whether we can embed the temporal information into the spatial one so the information in the two domains can be jointly learned once-only. In this work, we answer this question by presenting a simple yet powerful operator – temporal interlacing network (TIN). Instead of learning the temporal features, TIN fuses the two kinds of information by interlacing spatial representations from the past to the future, and vice versa. A differentiable interlacing target can be learned to control the interlacing process. In this way, a heavy temporal model is replaced by a simple interlacing operator. We theoretically prove that with a learnable interlacing target, TIN performs equivalently to the regularized temporal convolution network (r-TCN), but gains 4% more accuracy with 6x less latency on 6 challenging benchmarks. These results push the state-of-the-art performances of video understanding by a considerable margin. Not surprising, the ensemble model of the proposed TIN won the 1st place in the ICCV19 - Multi Moments in Time challenge.

Results and Models¶
Something-Something V1¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
inference time(video/s) |
gpu_mem(M) |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
height 100 |
8x4 |
ResNet50 |
ImageNet |
39.68 |
68.55 |
44.04 |
72.72 |
8 clips x 1 crop |
x |
6181 |
Something-Something V2¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
inference time(video/s) |
gpu_mem(M) |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
height 240 |
8x4 |
ResNet50 |
ImageNet |
54.78 |
82.18 |
56.48 |
83.45 |
8 clips x 1 crop |
x |
6185 |
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
inference time(video/s) |
gpu_mem(M) |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
short-side 256 |
8x4 |
ResNet50 |
TSM-Kinetics400 |
71.86 |
90.44 |
8 clips x 1 crop |
x |
6185 |
Here, we use finetune to indicate that we use TSM model trained on Kinetics-400 to finetune the TIN model on Kinetics-400.
备注
The reference topk acc are got by training the original repo #1aacd0c with no AverageMeter issue. The AverageMeter issue will lead to incorrect performance, so we fix it before running.
The gpus indicates the number of gpu we used to get the checkpoint. It is noteworthy that the configs we provide are used for 8 gpus as default. According to the Linear Scaling Rule, you may set the learning rate proportional to the batch size if you use different GPUs or videos per GPU, e.g., lr=0.01 for 4 GPUs x 2 video/gpu and lr=0.08 for 16 GPUs x 4 video/gpu.
The values in columns named after “reference” are the results got by training on the original repo, using the same model settings.
The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TIN model on Something-Something V1 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/tin/tin_imagenet-pretrained-r50_8xb6-1x1x8-40e_sthv1-rgb.py \
--work-dir work_dirs/tin_imagenet-pretrained-r50_8xb6-1x1x8-40e_sthv1-rgb randomness.seed=0 randomness.deterministic=True
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TIN model on Something-Something V1 dataset and dump the result to a json file.
python tools/test.py configs/recognition/tin/tin_imagenet-pretrained-r50_8xb6-1x1x8-40e_sthv1-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.json
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@article{shao2020temporal,
title={Temporal Interlacing Network},
author={Hao Shao and Shengju Qian and Yu Liu},
year={2020},
journal={AAAI},
}
TPN¶
Temporal Pyramid Network for Action Recognition
Abstract¶
Visual tempo characterizes the dynamics and the temporal scale of an action. Modeling such visual tempos of different actions facilitates their recognition. Previous works often capture the visual tempo through sampling raw videos at multiple rates and constructing an input-level frame pyramid, which usually requires a costly multi-branch network to handle. In this work we propose a generic Temporal Pyramid Network (TPN) at the feature-level, which can be flexibly integrated into 2D or 3D backbone networks in a plug-and-play manner. Two essential components of TPN, the source of features and the fusion of features, form a feature hierarchy for the backbone so that it can capture action instances at various tempos. TPN also shows consistent improvements over other challenging baselines on several action recognition datasets. Specifically, when equipped with TPN, the 3D ResNet-50 with dense sampling obtains a 2% gain on the validation set of Kinetics-400. A further analysis also reveals that TPN gains most of its improvements on action classes that have large variances in their visual tempos, validating the effectiveness of TPN.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
inference time(video/s) |
gpu_mem(M) |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8x8x1 |
short-side 320 |
8x2 |
ResNet50 |
None |
74.20 |
91.48 |
x |
x |
10 clips x 3 crop |
x |
6916 |
|||
8x8x1 |
short-side 320 |
8 |
ResNet50 |
ImageNet |
76.74 |
92.57 |
10 clips x 3 crop |
x |
6916 |
Something-Something V1¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
inference time(video/s) |
gpu_mem(M) |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
height 100 |
8x6 |
ResNet50 |
TSM |
51.87 |
79.67 |
x |
x |
8 clips x 3 crop |
x |
8828 |
备注
The gpus indicates the number of gpu we used to get the checkpoint. It is noteworthy that the configs we provide are used for 8 gpus as default. According to the Linear Scaling Rule, you may set the learning rate proportional to the batch size if you use different GPUs or videos per GPU, e.g., lr=0.01 for 4 GPUs x 2 video/gpu and lr=0.08 for 16 GPUs x 4 video/gpu.
The values in columns named after “reference” are the results got by testing the checkpoint released on the original repo and codes, using the same dataset with ours.
The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TPN model on Kinetics-400 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/tpn/tpn-slowonly_r50_8xb8-8x8x1-150e_kinetics400-rgb.py \
--work-dir work_dirs/tpn-slowonly_r50_8xb8-8x8x1-150e_kinetics400-rgb [--validate --seed 0 --deterministic]
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TPN model on Kinetics-400 dataset and dump the result to a json file.
python tools/test.py configs/recognition/tpn/tpn-slowonly_r50_8xb8-8x8x1-150e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{yang2020tpn,
title={Temporal Pyramid Network for Action Recognition},
author={Yang, Ceyuan and Xu, Yinghao and Shi, Jianping and Dai, Bo and Zhou, Bolei},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020},
}
TRN¶
Temporal Relational Reasoning in Videos
Abstract¶
Temporal relational reasoning, the ability to link meaningful transformations of objects or entities over time, is a fundamental property of intelligent species. In this paper, we introduce an effective and interpretable network module, the Temporal Relation Network (TRN), designed to learn and reason about temporal dependencies between video frames at multiple time scales. We evaluate TRN-equipped networks on activity recognition tasks using three recent video datasets - Something-Something, Jester, and Charades - which fundamentally depend on temporal relational reasoning. Our results demonstrate that the proposed TRN gives convolutional neural networks a remarkable capacity to discover temporal relations in videos. Through only sparsely sampled video frames, TRN-equipped networks can accurately predict human-object interactions in the Something-Something dataset and identify various human gestures on the Jester dataset with very competitive performance. TRN-equipped networks also outperform two-stream networks and 3D convolution networks in recognizing daily activities in the Charades dataset. Further analyses show that the models learn intuitive and interpretable visual common sense knowledge in videos.

Results and Models¶
Something-Something V1¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc (efficient/accurate) |
top5 acc (efficient/accurate) |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
31.60 / 33.65 |
60.15 / 62.22 |
16 clips x 10 crop |
42.94G |
26.64M |
Something-Something V2¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc (efficient/accurate) |
top5 acc (efficient/accurate) |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
47.65 / 51.20 |
76.27 / 78.42 |
16 clips x 10 crop |
42.94G |
26.64M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.There are two kinds of test settings for Something-Something dataset, efficient setting (center crop only) and accurate setting (three crop and
twice_sample).In the original repository, the author augments data with random flipping on something-something dataset, but the augmentation method may be wrong due to the direct actions, such as
push left to right. So, we replacedflipwithflip with label mapping, and change the testing methodTenCrop, which has five flipped crops, toTwice Sample & ThreeCrop.We use
ResNet50instead ofBNInceptionas the backbone of TRN. When TrainingTRN-ResNet50on sthv1 dataset in the original repository, we get top1 (top5) accuracy 30.542 (58.627) vs. ours 31.81 (60.47).
For more details on data preparation, you can refer to Something-something V1 and Something-something V2.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TRN model on sthv1 dataset in a deterministic option with periodic validation.
python tools/train.py configs/recognition/trn/trn_imagenet-pretrained-r50_8xb16-1x1x8-50e_sthv1-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TRN model on sthv1 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/trn/trn_imagenet-pretrained-r50_8xb16-1x1x8-50e_sthv1-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@article{zhou2017temporalrelation,
title = {Temporal Relational Reasoning in Videos},
author = {Zhou, Bolei and Andonian, Alex and Oliva, Aude and Torralba, Antonio},
journal={European Conference on Computer Vision},
year={2018}
}
TSM¶
TSM: Temporal Shift Module for Efficient Video Understanding
Abstract¶
The explosive growth in video streaming gives rise to challenges on performing video understanding at high accuracy and low computation cost. Conventional 2D CNNs are computationally cheap but cannot capture temporal relationships; 3D CNN based methods can achieve good performance but are computationally intensive, making it expensive to deploy. In this paper, we propose a generic and effective Temporal Shift Module (TSM) that enjoys both high efficiency and high performance. Specifically, it can achieve the performance of 3D CNN but maintain 2D CNN’s complexity. TSM shifts part of the channels along the temporal dimension; thus facilitate information exchanged among neighboring frames. It can be inserted into 2D CNNs to achieve temporal modeling at zero computation and zero parameters. We also extended TSM to online setting, which enables real-time low-latency online video recognition and video object detection. TSM is accurate and efficient: it ranks the first place on the Something-Something leaderboard upon publication; on Jetson Nano and Galaxy Note8, it achieves a low latency of 13ms and 35ms for online video recognition.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
73.18 |
90.56 |
8 clips x 10 crop |
32.88G |
23.87M |
|||
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
73.22 |
90.22 |
8 clips x 10 crop |
32.88G |
23.87M |
|||
1x1x16 |
224x224 |
8 |
ResNet50 |
ImageNet |
75.12 |
91.55 |
16 clips x 10 crop |
65.75G |
23.87M |
|||
1x1x8 (dense) |
224x224 |
8 |
ResNet50 |
ImageNet |
73.38 |
90.78 |
8 clips x 10 crop |
32.88G |
23.87M |
|||
1x1x8 |
224x224 |
8 |
ResNet50 (NonLocalDotProduct) |
ImageNet |
74.49 |
91.15 |
8 clips x 10 crop |
61.30G |
31.68M |
|||
1x1x8 |
224x224 |
8 |
ResNet50 (NonLocalGauss) |
ImageNet |
73.66 |
90.99 |
8 clips x 10 crop |
59.06G |
28.00M |
|||
1x1x8 |
224x224 |
8 |
ResNet50 (NonLocalEmbedGauss) |
ImageNet |
74.34 |
91.23 |
8 clips x 10 crop |
61.30G |
31.68M |
|||
1x1x8 |
224x224 |
8 |
MobileNetV2 |
ImageNet |
68.71 |
88.32 |
8 clips x 3 crop |
3.269G |
2.736M |
|||
1x1x16 |
224x224 |
8 |
MobileOne-S4 |
ImageNet |
74.38 |
91.71 |
16 clips x 10 crop |
48.65G |
13.72M |
Something-something V2¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
224x224 |
8 |
ResNet50 |
ImageNet |
62.72 |
87.70 |
8 clips x 3 crop |
32.88G |
23.87M |
|||
1x1x16 |
224x224 |
8 |
ResNet50 |
ImageNet |
64.16 |
88.61 |
16 clips x 3 crop |
65.75G |
23.87M |
|||
1x1x8 |
224x224 |
8 |
ResNet101 |
ImageNet |
63.70 |
88.28 |
8 clips x 3 crop |
62.66G |
42.86M |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
MoibleOne backbone supports reparameterization during inference. You can use the provided reparameterize tool to convert the checkpoint and switch to the deploy config file.
For more details on data preparation, you can refer to Kinetics400.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TSM model on Kinetics-400 dataset in a deterministic option.
python tools/train.py configs/recognition/tsm/tsm_imagenet-pretrained-r50_8xb16-1x1x8-50e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TSM model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/tsm/tsm_imagenet-pretrained-r50_8xb16-1x1x8-50e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{lin2019tsm,
title={TSM: Temporal Shift Module for Efficient Video Understanding},
author={Lin, Ji and Gan, Chuang and Han, Song},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2019}
}
@article{Nonlocal2018,
author = {Xiaolong Wang and Ross Girshick and Abhinav Gupta and Kaiming He},
title = {Non-local Neural Networks},
journal = {CVPR},
year = {2018}
}
TSN¶
Temporal segment networks: Towards good practices for deep action recognition
Abstract¶
Deep convolutional networks have achieved great success for visual recognition in still images. However, for action recognition in videos, the advantage over traditional methods is not so evident. This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos and learn these models given limited training samples. Our first contribution is temporal segment network (TSN), a novel framework for video-based action recognition. which is based on the idea of long-range temporal structure modeling. It combines a sparse temporal sampling strategy and video-level supervision to enable efficient and effective learning using the whole action video. The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network. Our approach obtains the state-the-of-art performance on the datasets of HMDB51 ( 69.4%) and UCF101 (94.2%). We also visualize the learned ConvNet models, which qualitatively demonstrates the effectiveness of temporal segment network and the proposed good practices.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x3 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
72.83 |
90.65 |
25 clips x 10 crop |
102.7G |
24.33M |
|||
1x1x5 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
73.80 |
91.21 |
25 clips x 10 crop |
102.7G |
24.33M |
|||
1x1x8 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
74.12 |
91.34 |
25 clips x 10 crop |
102.7G |
24.33M |
|||
dense-1x1x5 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
71.37 |
89.67 |
25 clips x 10 crop |
102.7G |
24.33M |
|||
1x1x8 |
MultiStep |
224x224 |
8 |
ResNet101 |
ImageNet |
75.89 |
92.07 |
25 clips x 10 crop |
195.8G |
43.32M |
Something-Something V2¶
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x8 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
35.51 |
67.09 |
25 clips x 10 crop |
102.7G |
24.33M |
|||
1x1x16 |
MultiStep |
224x224 |
8 |
ResNet50 |
ImageNet |
36.91 |
68.77 |
25 clips x 10 crop |
102.7G |
24.33M |
Using backbones from 3rd-party in TSN¶
It’s possible and convenient to use a 3rd-party backbone for TSN under the framework of MMAction2, here we provide some examples for:
[x] Backbones from MMClassification
[x] Backbones from MMPretrain
[x] Backbones from TorchVision
[x] Backbones from TIMM (pytorch-image-models)
frame sampling strategy |
scheduler |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1x1x3 |
MultiStep |
224x224 |
8 |
ResNext101 |
ImageNet |
72.95 |
90.36 |
25 clips x 10 crop |
200.3G |
42.95M |
|||
1x1x3 |
MultiStep |
224x224 |
8 |
DenseNet161 |
ImageNet |
72.07 |
90.15 |
25 clips x 10 crop |
194.6G |
27.36M |
|||
1x1x3 |
MultiStep |
224x224 |
8 |
Swin Transformer |
ImageNet |
77.03 |
92.61 |
25 clips x 10 crop |
386.7G |
87.15M |
|||
1x1x8 |
MultiStep |
224x224 |
8 |
Swin Transformer |
ImageNet |
79.22 |
94.20 |
25 clips x 10 crop |
386.7G |
87.15M |
|||
1x1x8 |
MultiStep |
224x224 |
8 |
MobileOne-S4 |
ImageNet |
73.65 |
91.32 |
25 clips x 10 crop |
76G |
13.72M |
Note that some backbones in TIMM are not supported due to multiple reasons. Please refer to PR #880 for details.
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size and the original batch size.The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
MoibleOne backbone supports reparameterization during inference. You can use the provided reparameterize tool to convert the checkpoint and switch to the deploy config file.
For more details on data preparation, you can refer to
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train TSN model on Kinetics-400 dataset in a deterministic option.
python tools/train.py configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py \
--seed=0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test TSN model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/tsn/tsn_imagenet-pretrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{wang2016temporal,
title={Temporal segment networks: Towards good practices for deep action recognition},
author={Wang, Limin and Xiong, Yuanjun and Wang, Zhe and Qiao, Yu and Lin, Dahua and Tang, Xiaoou and Van Gool, Luc},
booktitle={European conference on computer vision},
pages={20--36},
year={2016},
organization={Springer}
}
UniFormer¶
UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
Abstract¶
It is a challenging task to learn rich and multi-scale spatiotemporal semantics from high-dimensional videos, due to large local redundancy and complex global dependency between video frames. The recent advances in this research have been mainly driven by 3D convolutional neural networks and vision transformers. Although 3D convolution can efficiently aggregate local context to suppress local redundancy from a small 3D neighborhood, it lacks the capability to capture global dependency because of the limited receptive field. Alternatively, vision transformers can effectively capture long-range dependency by self-attention mechanism, while having the limitation on reducing local redundancy with blind similarity comparison among all the tokens in each layer. Based on these observations, we propose a novel Unified transFormer (UniFormer) which seamlessly integrates merits of 3D convolution and spatiotemporal self-attention in a concise transformer format, and achieves a preferable balance between computation and accuracy. Different from traditional transformers, our relation aggregator can tackle both spatiotemporal redundancy and dependency, by learning local and global token affinity respectively in shallow and deep layers. We conduct extensive experiments on the popular video benchmarks, e.g., Kinetics-400, Kinetics-600, and Something-Something V1&V2. With only ImageNet-1K pretraining, our UniFormer achieves 82.9%/84.8% top-1 accuracy on Kinetics-400/Kinetics-600, while requiring 10x fewer GFLOPs than other state-of-the-art methods. For Something-Something V1 and V2, our UniFormer achieves new state-of-the-art performances of 60.9% and 71.2% top-1 accuracy respectively.
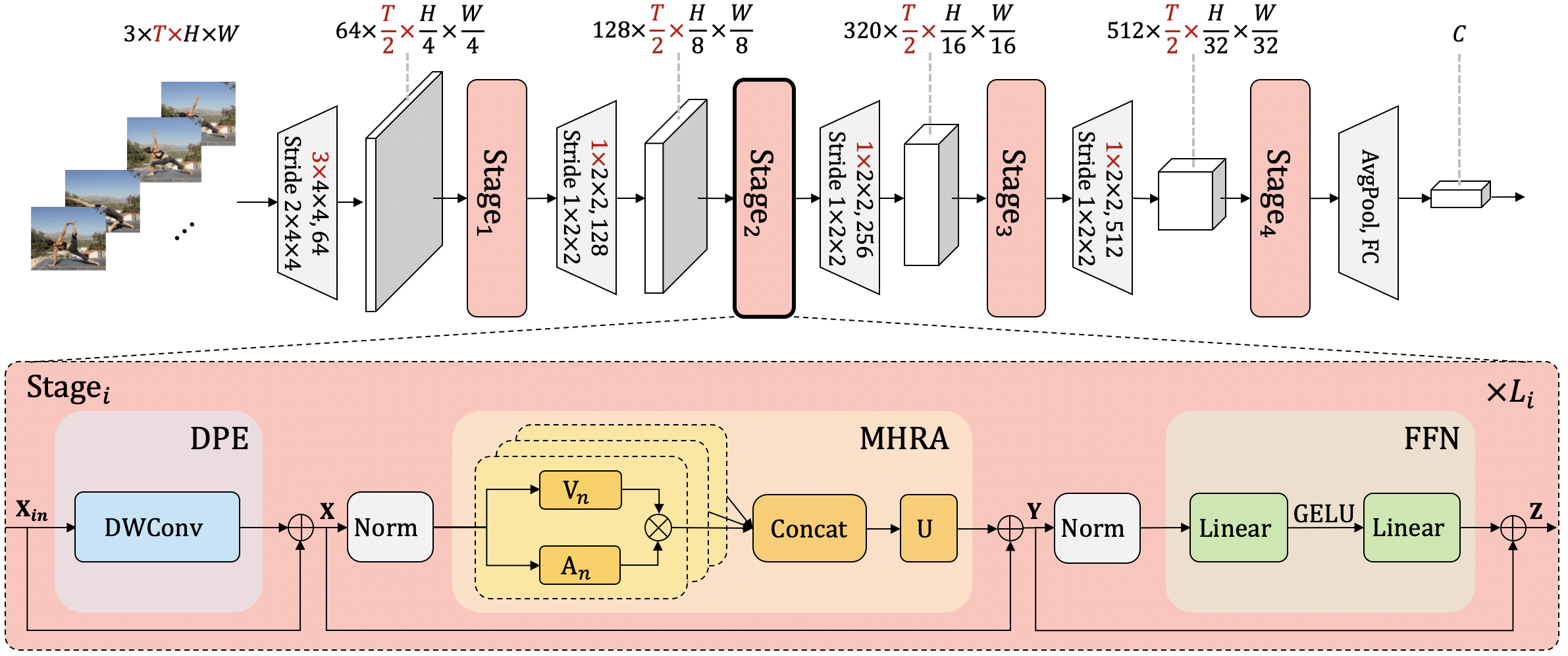
Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
mm-Kinetics top1 acc |
mm-Kinetics top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
short-side 320 |
UniFormer-S |
80.9 |
94.6 |
80.8 |
94.7 |
80.9 |
94.6 |
4 clips x 1 crop |
41.8G |
21.4M |
||
16x4x1 |
short-side 320 |
UniFormer-B |
82.0 |
95.0 |
82.0 |
95.1 |
82.0 |
95.0 |
4 clips x 1 crop |
96.7G |
49.8M |
||
32x4x1 |
short-side 320 |
UniFormer-B |
83.1 |
95.3 |
82.9 |
95.4 |
83.0 |
95.3 |
4 clips x 1 crop |
59G |
49.8M |
The models are ported from the repo UniFormer and tested on our data. Currently, we only support the testing of UniFormer models, training will be available soon.
The values in columns named after “reference” are the results of the original repo.
The values in
top1/5 accis tested on the same data list as the original repo, and the label map is provided by UniFormer. The total videos are available at Kinetics400 (BaiduYun password: g5kp), which consists of 19787 videos.The values in columns named after “mm-Kinetics” are the testing results on the Kinetics dataset held by MMAction2, which is also used by other models in MMAction2. Due to the differences between various versions of Kinetics dataset, there is a little gap between
top1/5 accandmm-Kinetics top1/5 acc. For a fair comparison with other models, we report both results here. Note that we simply report the inference results, since the training set is different between UniFormer and other models, the results are lower than that tested on the author’s version.Since the original models for Kinetics-400/600/700 adopt different label file, we simply map the weight according to the label name. New label map for Kinetics-400/600/700 can be found here.
Due to some difference between SlowFast and MMAction2, there are some gaps between their performances.
For more details on data preparation, you can refer to preparing_kinetics.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test UniFormer-S model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/uniformer/uniformer-small_imagenet1k-pre_16x4x1_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{
li2022uniformer,
title={UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning},
author={Kunchang Li and Yali Wang and Gao Peng and Guanglu Song and Yu Liu and Hongsheng Li and Yu Qiao},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=nBU_u6DLvoK}
}
UniFormerV2¶
UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer
Abstract¶
Learning discriminative spatiotemporal representation is the key problem of video understanding. Recently, Vision Transformers (ViTs) have shown their power in learning long-term video dependency with self-attention. Unfortunately, they exhibit limitations in tackling local video redundancy, due to the blind global comparison among tokens. UniFormer has successfully alleviated this issue, by unifying convolution and self-attention as a relation aggregator in the transformer format. However, this model has to require a tiresome and complicated image-pretraining phrase, before being finetuned on videos. This blocks its wide usage in practice. On the contrary, open-sourced ViTs are readily available and well-pretrained with rich image supervision. Based on these observations, we propose a generic paradigm to build a powerful family of video networks, by arming the pretrained ViTs with efficient UniFormer designs. We call this family UniFormerV2, since it inherits the concise style of the UniFormer block. But it contains brand-new local and global relation aggregators, which allow for preferable accuracy-computation balance by seamlessly integrating advantages from both ViTs and UniFormer. Without any bells and whistles, our UniFormerV2 gets the state-of-the-art recognition performance on 8 popular video benchmarks, including scene-related Kinetics-400/600/700 and Moments in Time, temporal-related Something-Something V1/V2, untrimmed ActivityNet and HACS. In particular, it is the first model to achieve 90% top-1 accuracy on Kinetics-400, to our best knowledge.
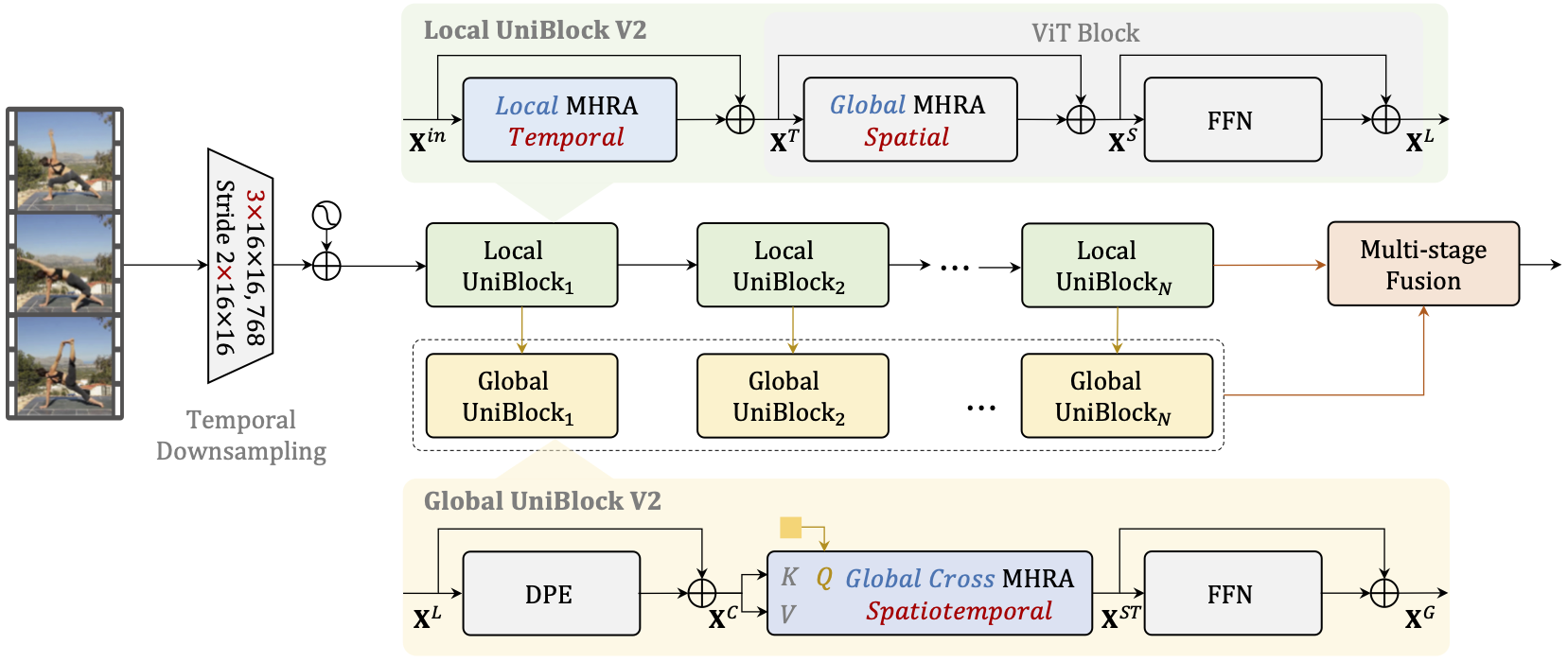
Results and Models¶
Kinetics-400¶
uniform sampling |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
mm-Kinetics top1 acc |
mm-Kinetics top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8 |
short-side 320 |
UniFormerV2-B/16 |
clip |
- |
- |
84.3 |
96.4 |
84.4 |
96.3 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
short-side 320 |
UniFormerV2-B/16 |
clip-kinetics710 |
- |
- |
85.6 |
97.0 |
85.8 |
97.1 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
short-side 320 |
UniFormerV2-L/14* |
clip-kinetics710 |
88.7 |
98.1 |
88.8 |
98.1 |
88.7 |
98.1 |
4 clips x 3 crop |
0.7T |
354M |
- |
||
16 |
short-side 320 |
UniFormerV2-L/14* |
clip-kinetics710 |
89.0 |
98.2 |
89.1 |
98.2 |
89.0 |
98.2 |
4 clips x 3 crop |
1.3T |
354M |
- |
||
32 |
short-side 320 |
UniFormerV2-L/14* |
clip-kinetics710 |
89.3 |
98.2 |
89.3 |
98.2 |
89.4 |
98.2 |
2 clips x 3 crop |
2.7T |
354M |
- |
||
32 |
short-side 320 |
UniFormerV2-L/14@336* |
clip-kinetics710 |
89.5 |
98.4 |
89.7 |
98.3 |
89.5 |
98.4 |
2 clips x 3 crop |
6.3T |
354M |
- |
Kinetics-600¶
uniform sampling |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
mm-Kinetics top1 acc |
mm-Kinetics top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8 |
Raw |
UniFormerV2-B/16 |
clip-kinetics710 |
- |
- |
86.1 |
97.2 |
86.4 |
97.3 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
89.0 |
98.3 |
89.0 |
98.2 |
87.5 |
98.0 |
4 clips x 3 crop |
0.7T |
354M |
- |
||
16 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
89.4 |
98.3 |
89.4 |
98.3 |
87.8 |
98.0 |
4 clips x 3 crop |
1.3T |
354M |
- |
||
32 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
89.2 |
98.3 |
89.5 |
98.3 |
87.7 |
98.1 |
2 clips x 3 crop |
2.7T |
354M |
- |
||
32 |
Raw |
UniFormerV2-L/14@336* |
clip-kinetics710 |
89.8 |
98.5 |
89.9 |
98.5 |
88.8 |
98.3 |
2 clips x 3 crop |
6.3T |
354M |
- |
Kinetics-700¶
uniform sampling |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
mm-Kinetics top1 acc |
mm-Kinetics top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8 |
Raw |
UniFormerV2-B/16 |
clip |
- |
- |
75.8 |
92.8 |
75.9 |
92.9 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
Raw |
UniFormerV2-B/16 |
clip-kinetics710 |
- |
- |
76.3 |
92.7 |
76.3 |
92.9 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
80.8 |
95.2 |
80.8 |
95.4 |
79.4 |
94.8 |
4 clips x 3 crop |
0.7T |
354M |
- |
||
16 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
81.2 |
95.6 |
81.2 |
95.6 |
79.2 |
95.0 |
4 clips x 3 crop |
1.3T |
354M |
- |
||
32 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710 |
81.4 |
95.7 |
81.5 |
95.7 |
79.8 |
95.3 |
2 clips x 3 crop |
2.7T |
354M |
- |
||
32 |
Raw |
UniFormerV2-L/14@336* |
clip-kinetics710 |
82.1 |
96.0 |
82.1 |
96.1 |
80.6 |
95.6 |
2 clips x 3 crop |
6.3T |
354M |
- |
MiTv1¶
uniform sampling |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8 |
Raw |
UniFormerV2-B/16 |
clip-kinetics710-kinetics400 |
42.3 |
71.5 |
42.6 |
71.7 |
4 clips x 3 crop |
0.1T |
115M |
|||
8 |
Raw |
UniFormerV2-L/14* |
clip-kinetics710-kinetics400 |
47.0 |
76.1 |
47.0 |
76.1 |
4 clips x 3 crop |
0.7T |
354M |
- |
||
8 |
Raw |
UniFormerV2-L/14@336* |
clip-kinetics710-kinetics400 |
47.7 |
76.8 |
47.8 |
76.0 |
4 clips x 3 crop |
1.6T |
354M |
- |
Kinetics-710¶
uniform sampling |
resolution |
backbone |
pretrain |
top1 acc |
top5 acc |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
8 |
Raw |
UniFormerV2-B/16* |
clip |
78.9 |
94.2 |
|||
8 |
Raw |
UniFormerV2-L/14* |
clip |
- |
- |
- |
||
8 |
Raw |
UniFormerV2-L/14@336* |
clip |
- |
- |
- |
The models with * are ported from the repo UniFormerV2 and tested on our data. Due to computational limitations, we only support reliable training config for base model (i.e. UniFormerV2-B/16).
The values in columns named after “reference” are the results of the original repo.
The values in
top1/5 accis tested on the same data list as the original repo, and the label map is provided by UniFormerV2.The values in columns named after “mm-Kinetics” are the testing results on the Kinetics dataset held by MMAction2, which is also used by other models in MMAction2. Due to the differences between various versions of Kinetics dataset, there is a little gap between
top1/5 accandmm-Kinetics top1/5 acc. For a fair comparison with other models, we report both results here. Note that we simply report the inference results, since the training set is different between UniFormer and other models, the results are lower than that tested on the author’s version.Since the original models for Kinetics-400/600/700 adopt different label file, we simply map the weight according to the label name. New label map for Kinetics-400/600/700 can be found here.
Due to some differences between SlowFast and MMAction2, there are some gaps between their performances.
Kinetics-710 is used for pretraining, which helps improve the performance on other datasets efficiently. You can find more details in the paper. We also map the wegiht for Kinetics-710 checkpoints, you can find the label map here.
For more details on data preparation, you can refer to
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test UniFormerV2-B/16 model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/uniformerv2/uniformerv2-base-p16-res224_clip-kinetics710-pre_u8_kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@article{Li2022UniFormerV2SL,
title={UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer},
author={Kunchang Li and Yali Wang and Yinan He and Yizhuo Li and Yi Wang and Limin Wang and Y. Qiao},
journal={ArXiv},
year={2022},
volume={abs/2211.09552}
}
VideoMAE¶
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Abstract¶
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking with an extremely high ratio. This simple design makes video reconstruction a more challenging self-supervision task, thus encouraging extracting more effective video representations during this pre-training process. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables a higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets is an important issue. Notably, our VideoMAE with the vanilla ViT can achieve 87.4% on Kinetics-400, 75.4% on Something-Something V2, 91.3% on UCF101, and 62.6% on HMDB51, without using any extra data.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
short-side 320 |
ViT-B |
81.3 |
95.0 |
81.5 [VideoMAE] |
95.1 [VideoMAE] |
5 clips x 3 crops |
180G |
87M |
ckpt [1] |
|
16x4x1 |
short-side 320 |
ViT-L |
85.3 |
96.7 |
85.2 [VideoMAE] |
96.8 [VideoMAE] |
5 clips x 3 crops |
597G |
305M |
ckpt [1] |
[1] The models are ported from the repo VideoMAE and tested on our data. Currently, we only support the testing of VideoMAE models, training will be available soon.
The values in columns named after “reference” are the results of the original repo.
The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to preparing_kinetics.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test ViT-base model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/videomae/vit-base-p16_videomae-k400-pre_16x4x1_kinetics-400.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
VideoMAE V2¶
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Abstract¶
Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
top1 acc |
top5 acc |
reference top1 acc |
reference top5 acc |
testing protocol |
FLOPs |
params |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|---|---|---|
16x4x1 |
short-side 320 |
ViT-S |
83.6 |
96.3 |
83.7 [VideoMAE V2] |
96.2 [VideoMAE V2] |
5 clips x 3 crops |
57G |
22M |
ckpt [1] |
|
16x4x1 |
short-side 320 |
ViT-B |
86.6 |
97.3 |
86.6 [VideoMAE V2] |
97.3 [VideoMAE V2] |
5 clips x 3 crops |
180G |
87M |
ckpt [1] |
[1] The models were distilled from the VideoMAE V2-g model. Specifically, models are initialized with VideoMAE V2 pretraining, then distilled on Kinetics 710 dataset. They are ported from the repo VideoMAE V2 and tested on our data. The VideoMAE V2-g model can be obtained from the original repository. Currently, we only support the testing of VideoMAE V2 models.
The values in columns named after “reference” are the results of the original repo.
The validation set of Kinetics400 we used consists of 19796 videos. These videos are available at Kinetics400-Validation. The corresponding data list (each line is of the format ‘video_id, num_frames, label_index’) and the label map are also available.
For more details on data preparation, you can refer to preparing_kinetics.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test ViT-base model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/videomaev2/vit-base-p16_videomaev2-vit-g-dist-k710-pre_16x4x1_kinetics-400.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@misc{wang2023videomaev2,
title={VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking},
author={Limin Wang and Bingkun Huang and Zhiyu Zhao and Zhan Tong and Yinan He and Yi Wang and Yali Wang and Yu Qiao},
year={2023},
eprint={2303.16727},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
X3D¶
X3D: Expanding Architectures for Efficient Video Recognition
Abstract¶
This paper presents X3D, a family of efficient video networks that progressively expand a tiny 2D image classification architecture along multiple network axes, in space, time, width and depth. Inspired by feature selection methods in machine learning, a simple stepwise network expansion approach is employed that expands a single axis in each step, such that good accuracy to complexity trade-off is achieved. To expand X3D to a specific target complexity, we perform progressive forward expansion followed by backward contraction. X3D achieves state-of-the-art performance while requiring 4.8x and 5.5x fewer multiply-adds and parameters for similar accuracy as previous work. Our most surprising finding is that networks with high spatiotemporal resolution can perform well, while being extremely light in terms of network width and parameters. We report competitive accuracy at unprecedented efficiency on video classification and detection benchmarks.

Results and Models¶
Kinetics-400¶
frame sampling strategy |
resolution |
backbone |
top1 10-view |
top1 30-view |
reference top1 10-view |
reference top1 30-view |
config |
ckpt |
|---|---|---|---|---|---|---|---|---|
13x6x1 |
160x160 |
X3D_S |
73.2 |
73.3 |
73.1 [SlowFast] |
73.5 [SlowFast] |
ckpt[1] |
|
16x5x1 |
224x224 |
X3D_M |
75.2 |
76.4 |
75.1 [SlowFast] |
76.2 [SlowFast] |
ckpt[1] |
[1] The models are ported from the repo SlowFast and tested on our data. Currently, we only support the testing of X3D models, training will be available soon.
The values in columns named after “reference” are the results got by testing the checkpoint released on the original repo and codes, using the same dataset with ours.
The validation set of Kinetics400 we used is same as the repo SlowFast, which is available here.
For more details on data preparation, you can refer to Kinetics400.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test X3D model on Kinetics-400 dataset and dump the result to a pkl file.
python tools/test.py configs/recognition/x3d/x3d_s_13x6x1_facebook-kinetics400-rgb.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@misc{feichtenhofer2020x3d,
title={X3D: Expanding Architectures for Efficient Video Recognition},
author={Christoph Feichtenhofer},
year={2020},
eprint={2004.04730},
archivePrefix={arXiv},
primaryClass={cs.CV}
}